Hazelcast 分布式共享数据
技术背景
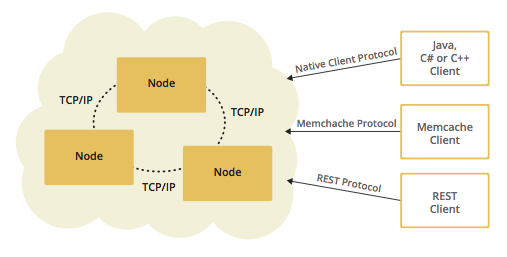
Hazelcast 是一个开源的分布式计算平台,它提供了一种在多个节点之间共享数据的方法。Hazelcast 支持多种数据结构,如 Map、Set、List、Queue 等,并提供了丰富的配置选项,以满足不同场景的需求。
Hazelcast 可以用于以下场景:
- 分布式缓存:在分布式系统中,可以使用 Hazelcast 作为缓存层,将热点数据存储在内存中,提高系统的性能。
- 分布式计数器:使用 Hazelcast 的 IMap 数据结构,可以实现分布式计数器,方便地对分布式系统中的事件进行计数。
- 分布式消息队列:Hazelcast 提供了与 Apache Kafka 集成的功能,可以将消息发送到 Kafka,然后在其他节点上消费这些消息。
- 分布式数据库:Hazelcast 可以作为分布式数据库的一部分,提供高可用性和容错性。
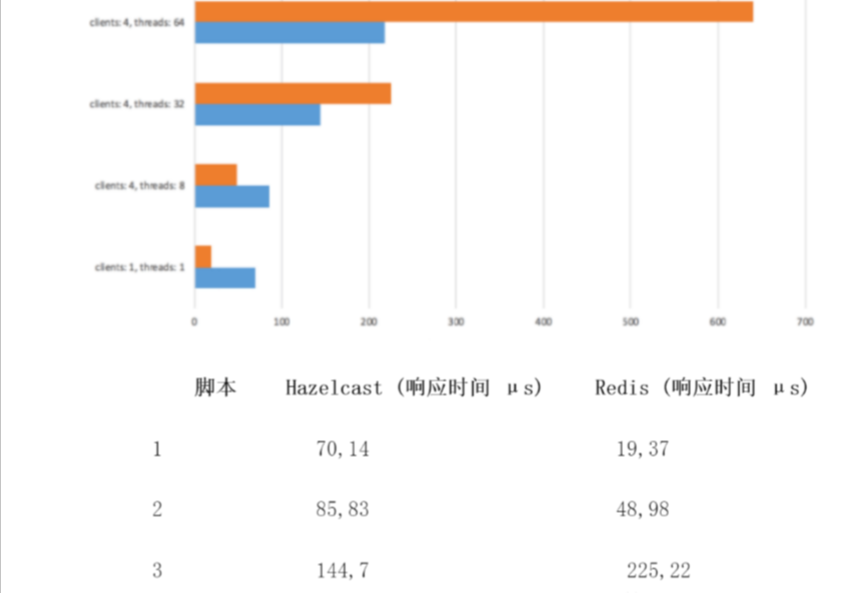
Redis和Hazelcast进行了效率的对比,红色是Redis,蓝色是Hazelcast,根据结果。Redis在低数据负载的时候响应比 Hazelcast 表现更好,而在数据负载和并发请求增加时则表现相反。在不常见的大环境(如我们在脚本4)我们可以看到 Redis的平均响应时间剧烈的增长。Hazelcast 响应时间虽然也随着线程数增加而增长,但是这种增长要稳定得多,而且不像 Redis 表现的那样是指数级。
Spring Boot 使用例子
1、在 Spring Boot 项目中,首先需要在 pom.xml 文件中添加 Hazelcast 的依赖:
<!-- https://mvnrepository.com/artifact/com.hazelcast/hazelcast -->
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
<version>5.3.1</version>
</dependency>
Gradle(build.gradle):
compile com.hazelcast:hazelcast:${hazelcast.vertsion}
2、接下来,在 application.properties 或 application.yml 文件中配置 Hazelcast 集群:
hazelcast:
network:
join:
multicast:
enabled: true
这里配置了多播:Hazelcast使用多播协议来进行集群发现和成员管理。可以通过配置启用多播,让Hazelcast节点能够自动加入集群。
多播(Multicast)是一种网络通信方式,用于将数据包从一个发送者传输到多个接收者。与广播不同的是,多播是一种一对多的通信方式,只有那些已经加入特定多播组的主机才能接收到多播数据包。
在分布式系统中,多播可以用于集群节点之间的发现和通信。Hazelcast中使用多播协议来进行集群发现和成员管理,允许新的节点自动加入集群并与其他节点通信。这种方式能够简化集群配置和节点发现的处理,使得集群的扩展和管理更加容易。
3、先创一个建 Hazelcast 节点:
//org.palm.hazelcast.getstart.HazelcastGetStartServerMaster
public class HazelcastGetStartServerMaster {
public static void main(String[] args) {
// 创建一个 hazelcastInstance实例
HazelcastInstance instance = Hazelcast.newHazelcastInstance();
// 创建集群Map
Map<Integer, String> clusterMap = instance.getMap("MyMap");
clusterMap.put(1, "Hello hazelcast map!");
// 创建集群Queue
Queue<String> clusterQueue = instance.getQueue("MyQueue");
clusterQueue.offer("Hello hazelcast!");
clusterQueue.offer("Hello hazelcast queue!");
}
}
上面的代码使用 Hazelcast 实例创建了一个节点。然后通过这个实例创建了一个分布式的Map和分布式的Queue,并向这些数据结构中添加了数据。运行这个main方法,会在console看到以下内容:
Members [1] {
Member [192.168.2.199]:5701 this
}
- 随后再创建另外一个节点:
// org.palm.hazelcast.getstart.HazelcastGetStartServerSlave
public class HazelcastGetStartServerSlave {
public static void main(String[] args) {
//创建一个 hazelcastInstance实例
HazelcastInstance instance = Hazelcast.newHazelcastInstance();
Map<Integer, String> clusterMap = instance.getMap("MyMap");
Queue<String> clusterQueue = instance.getQueue("MyQueue");
System.out.println("Map Value:" + clusterMap.get(1));
System.out.println("Queue Size :" + clusterQueue.size());
System.out.println("Queue Value 1:" + clusterQueue.poll());
System.out.println("Queue Value 2:" + clusterQueue.poll());
System.out.println("Queue Size :" + clusterQueue.size());
}
}
该节点的作用是从Map、Queue中读取数据并输出。运行会看到以下输出
Members [2] {
Member [192.168.199]:5701
Member [192.168.2.199]:5702 this
}
至此,2个节点的集群创建完毕。第一个节点向map实例添加了{key:1,value:"Hello hazelcast map!"},向queue实例添加[“Hello hazelcast!”,“Hello hazelcast queue!”],第二个节点读取并打印这些数据。

- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝